A Complete Python Action¶
Note
It is recommended to read The Basics before starting this guide.
In this tutorial, we will write a custom action. For educational purposes, we'll automate the investigation of a made-up (but realistic) error scenario.
The scenario¶
Note
It is recommended to follow along the described scenario and run all the commands on a test cluster.
Let's imagine that you want to create and deploy a new pod with the ngnix image.
Being the smart person that you are, you decide to save time by copy-pasting an existing YAML file. You change the pod name and image to ngnix.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
spoiler: alert
You start the pod by running the following command:
$ kubectl apply -f nginx-pod.yaml
pod/nginx created
For some reason the pod doesn't start (note it’s "Pending" Status):
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 0/1 Pending 0 5h19m
You wait a few minutes, but it remains the same.
To investigate you look at the event log:
kubectl get event --field-selector involvedObject.name=nginx
LAST SEEN TYPE REASON OBJECT MESSAGE
64s Warning FailedScheduling pod/nginx 0/1 nodes are available: 1 node(s) didn't match Pod's node affinity/selector.
Aha! "1 node(s) didn't match Pod's node affinity/selector." ALRIGHT!
Note
You can see this event on an informative timeline in Robusta UI. Check it out!
Wait, what does it mean? 😖 (Hint: Check the YAML config for the spoiler)
After searching online for some time, you find out that the YAML file you copied had a “nodeSelector” with the key-value "spoiler: alert", which means that it can only be scheduled on nodes (machines) that have this configuration 🤦♂️.
From the docs:
You can constrain a Pod so that it is restricted to run on particular node(s), or to prefer to run on particular nodes. There are several ways to do this and the recommended approaches all use label selectors to facilitate the selection. Often, you do not need to set any such constraints ...
So you comment out those lines, run kubectl apply again, and all is well.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
# nodeSelector:
# spoiler: alert
Wouldn't it be nice if we could automate the detection of issues like this?
Note
Make sure to clean up the pod from this section by running kubectl delete pod nginx
Automating the detection with a Robusta Playbook¶
What we need to do?¶
A playbook consists of two things:
Trigger - We’re going to use a built in trigger
Action - We’re going to write our own action!
Finding the correct trigger¶
What is the correct trigger for the job? We can think of two triggers that may fit:
Creation of a new pod (because we create a new pod, ‘ngnix’)
A Kubernetes Event is fired (because we ran kubectl get event to find out the scheduling error)
Let’s look at the Trigger section about Kubernetes (API Server), and try to find out triggers for both. Go ahead and try to find them!
Okay! We find on_pod_create and on_event_create
We'll use on_event_create in this tutorial because it will be easier to identify scheduling issues by looking at the event.
Writing the action¶
Now we need to write code that checks this event and reports it. To find the correct event class that matches our trigger on_event_create. please take a look at Events and Triggers.
Okay! We find out it’s EventEvent!
So we need to get the information, check for the scenario, and then report it (for more information about reporting it see Creating Findings)
Let’s name our action report_scheduling_failure, and write everything in a python file:
from robusta.api import *
@action
def report_scheduling_failure(event: EventEvent): # We use EventEvent to get the event object.
actual_event = event.get_event()
print(f"This print will be shown in the robusta logs={actual_event}")
if actual_event.type.casefold() == f'Warning'.casefold() and \
actual_event.reason.casefold() == f'FailedScheduling'.casefold() and \
actual_event.involvedObject.kind.casefold() == f'Pod'.casefold():
_report_failed_scheduling(event, actual_event.involvedObject.name, actual_event.message)
def _report_failed_scheduling(event: EventEvent, pod_name: str, message: str):
custom_message = ""
if "affinity/selector" in message:
custom_message = "Your pod has a node 'selector' configured, which means it can't just run on any node. For more info, see: https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#nodeselector"
# this is how you send data to slack or other destinations
# Note - is it sometimes better to create a Finding object instead of calling event.add_enrichment, but this is out of the scope of this tutorial
event.add_enrichment([
MarkdownBlock(f"Failed to schedule a pod named '{pod_name}'!\nerror: {message}\n\n{custom_message}"),
])
Before we proceed, we need to enable local playbook repositories in Robusta.
Follow this quick guide to learn how to package your python file for Robusta: Creating Playbook Repositories
Let’s push the new action to Robusta
robusta playbooks push <PATH_TO_LOCAL_PLAYBOOK_FOLDER>
Use this useful debugging commands to make sure your action ( report_scheduling_failure) is loaded:
$ robusta logs # get robusta logs, see errors, see our playbook loaded
...
2022-08-03 10:53:14.116 INFO importing actions from my_playbook_repo.report_scheduling_failure
...
$ robusta playbooks list-dirs # get see if you custom action package was loaded
======================================================================
Listing playbooks directories
======================================================================
======================================================================
Stored playbooks directories:
robusta-pending-pod-playbook
======================================================================
Connecting the trigger to the action - a playbook is born!¶
We need to add a custom playbook that this action it in the generated_values.yaml.
# SNIP! existing contents of the file removed for clarity...
# This is your custom playbook
customPlaybooks:
- triggers:
- on_event_create: {}
actions:
- report_scheduling_failure: {}
# This enables loading custom playbooks
playbooksPersistentVolume: true
Time to update Robusta’s config with the new generated_config.yaml:
helm upgrade robusta robusta/robusta --values=generated_values.yaml
After a minute or two Robusta will be ready. Let's run this command to see that the new playbook is loaded:
$ robusta logs # get robusta logs, see no errors
...
...
$ robusta playbooks list # see all the playbooks. Run it after a few minutes
...
--------------------------------------
triggers:
- on_event_create: {}
actions:
- report_scheduling_failure: {}
--------------------------------------
...
Great!
Note
If you haven't already, make sure to clean up the pod from the last section by running kubectl delete pod nginx
Now for the final check, let's deploy the mis-configured pod again:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
spoiler: alert
And start the pod by running the following command:
$ kubectl apply -f nginx-pod.yaml
pod/nginx created
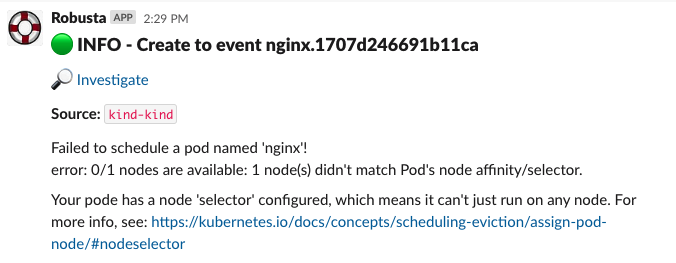
Now, Check out the Slack channel (sink), for example:
Example Slack Message
Cleaning up¶
kubectl delete pod nginx # delete the pod
robusta playbooks delete <PLAYBOOK_FOLDER> # remove the playbook we just added from Robusta
# Remove "customPlaybooks" and "playbooksPersistentVolume" from you config, and then run helm upgrade
helm upgrade robusta robusta/robusta --values=generated_values.yaml
Summary¶
We learned how to solve a real problem (pod not scheduling) only once and have Robusta automate it in the future for all our happy co-workers (and future us) to enjoy.
This example of an unschedulable pod is actually covered by Robusta out of the box (if you enable the builtin Prometheus stack) but you can see how easy it is to track any error you like and send it to a notifications system with extra data.