Findings API¶
Motivation¶
Playbooks should use the Findings API to display output. They should not send output directly to Slack or other destinations.
By using the Findings API, your playbook will support Slack, MSTeams, and other sinks.
Basic Usage¶
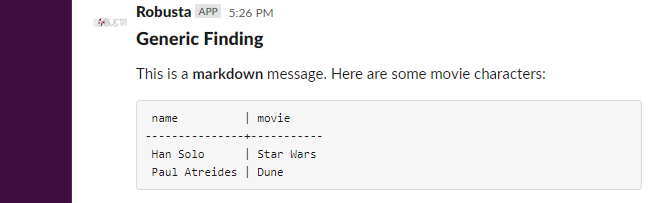
Playbooks can call event.add_enrichment to add to the playbook’s output. For example:
@action
def test_playbook(event: ExecutionBaseEvent):
event.add_enrichment(
[
MarkdownBlock(
"This is a *markdown* message. Here are some movie characters:"
),
TableBlock(
[["Han Solo", "Star Wars"], ["Paul Atreides", "Dune"]],
["name", "movie"],
),
]
)
When playbooks finish running, their output is sent to the configured sinks. Here is output for the above example:
Core Concepts¶
The Findings API has four important concepts:
- Finding
An event, like a Prometheus alert or a deployment update.
- Enrichment
Details about a Finding, like the labels for a Prometheus alert or a deployment’s YAML before and after the update.
- Block
A visual element, like a paragraph, an image, or a table.
- Sink
A destination Findings are sent to, like Slack, MSTeams, Kafka topics
Here is an example showing the above concepts:
![digraph {
compound=true;
rankdir=TB
fixedsize=true;
node [ fontname="Handlee"
fixedsize=true
width=2
height=1
];
subgraph cluster_finding {
label=<Finding<BR /><BR /><I><FONT POINT-SIZE="9">HighCPU Alert</FONT></I>>;
subgraph cluster_enrichment1 {
label=<Enrichment<BR /><BR /><I><FONT POINT-SIZE="9">Prometheus Labels</FONT></I>>;
block1 [
label = <TableBlock<BR /><BR /><I><FONT POINT-SIZE="9">pod=my-pod<BR />namespace=default</FONT></I>>;
]
}
subgraph cluster_enrichment2 {
label=<Enrichment<BR /><BR /><I><FONT POINT-SIZE="9">CPU Profile Result</FONT></I>>;
rank=same;
block2 [
label = <MarkdownBlock<BR /><BR /><I><FONT POINT-SIZE="9">Explanation</FONT></I>>;
]
block3 [
label = <FileBlock<BR /><BR /><I><FONT POINT-SIZE="9">Profiler Result</FONT></I>>;
]
}
}
slack_sink [
label = <Slack Sink>;
]
msteams_sink [
label = <MSTeams Sink>;
]
more_sinks [
label = <...>;
]
block2 -> slack_sink, more_sinks, msteams_sink [ltail=cluster_finding minlen=2];
}](../_images/graphviz-7bd06e4d41c145e124f47792044fb7b01d190ade.png)
Advanced Usage¶
It is possible to customize a findings name, override the default finding for events, and more.
But we haven’t documented it yet. Please consult the source code.
Block Types¶
Every Block represents a different type of visual data. Here are the possible Blocks:
|
A Block of Markdown |
|
A file of any type. |
|
A visual separator between other blocks |
|
Text formatted as a header |
|
A list of items, nicely formatted |
|
Table display of a list of lists. |
|
A nicely formatted Kubernetes objects, with a subset of the fields shown |
|
A diff between two versions of a Kubernetes object |
|
Json data |
|
A set of buttons that allows callbacks from the sink - for example, a button in Slack that will trigger another action when clicked |
Note
Not all block types are supported by all sinks. If an unsupported block arrives at a sink, it will be ignored
Reference¶
- class MarkdownBlock(text, dedent=False)[source]¶
A Block of Markdown
- Parameters
text (
str) – one or more paragraphs of Markdown markupdedent (
bool) – if True, remove common indentation so that you can use multi-line docstrings.
A simple example:
MarkdownBlock("Hi, *I'm bold* and _I'm italic_")
Things can get hairy when using writing content across multiple lines:
MarkdownBlock( "# This is a header \n\n" "And this is a paragraph. " "Same paragraph. A new string on each line prevents Python from adding newlines." ),
For convenience, use
strip_whitespace=Trueand multiline strings:MarkdownBlock(""" Due to strip_whitespace=True this is all one paragraph despite indentation and newlines. """, strip_whitespace=True)
- class FileBlock(filename, contents)[source]¶
A file of any type. Used for images, log files, binary files, and more.
- Parameters
filename (
str) – the file’s namecontents (
bytes) – the file’s contents
Examples:
FileBlock("test.txt", "this is the file's contents")
- class DividerBlock(**data)[source]¶
A visual separator between other blocks
Create a new model by parsing and validating input data from keyword arguments.
Raises ValidationError if the input data cannot be parsed to form a valid model.
- class ListBlock(items)[source]¶
A list of items, nicely formatted
- Parameters
items (
List[str]) – a list of strings
- class TableBlock(rows, headers=(), column_renderers={})[source]¶
Table display of a list of lists.
- Parameters
rows (
List[List]) – a list of rows. each row is a list of columnsheaders (
Sequence[str]) – names of each column
- class KubernetesFieldsBlock(k8s_obj, fields, explanations={})[source]¶
A nicely formatted Kubernetes objects, with a subset of the fields shown
- Parameters
k8s_obj (
HikaruDocumentBase) – a kubernetes objectfields (
List[str]) – a list of fields to display. for example [“metadata.name”, “metadata.namespace”]explanations (
Dict[str,str]) – an explanation for each field. for example {“metdata.name”: “the pods name”}
- class KubernetesDiffBlock(interesting_diffs, old, new)[source]¶
A diff between two versions of a Kubernetes object
- Parameters
interesting_diffs (
List[DiffDetail]) – parts of the diff to emphasize - some sinks will only show these to save spaceold (
Optional[HikaruDocumentBase]) – the old version of the objectnew (
Optional[HikaruDocumentBase]) – the new version of the object